6 - Attention is All You Need
背景
减少顺序计算的目标构成了扩展神经GPU,ByteNet和ConvS2S的基础,所有这些都使用卷积神经网络作为基本构建块,并行计算所有输入和输出位置的隐藏表示。在这些模型中,关联来自两个任意输入或输出位置的信号所需的操作数量随着位置之间距离的增长而增长,对于ConvS2S呈线性增长,对于ByteNet呈对数增长。这使得学习远程位置之间的依赖性变得更加困难。在transformer中,这将被减少到恒定的操作次数,尽管由于平均注意力加权位置而导致有效分辨率降低,这是我们与多头注意力相抵消的效果。
自我注意力(self-attention),有时称为内部关注是关联机制,通过关联单个序列的不同位置来计算序列的表示。自我注意力已经成功地用于各种任务,包括阅读理解,抽象概括,文本蕴涵和学习任务独立的句子表示。端到端存储器网络基于循环注意机制而不是序列对齐重复,并且已经证明在简单语言问答和语言建模任务上表现良好。
然而,据我们所知,transformer是第一个完全依靠自我注意力(self-attention)的转换模型来计算其输入和输出的表示,而不使用序列对齐的RNN或卷积。
模型框架
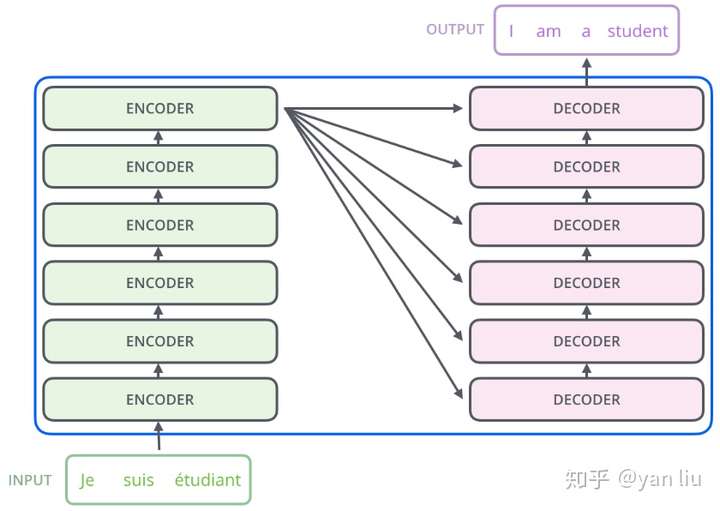
大多数竞争性神经序列转导模型具有编码器 - 解码器结构。 这里,编码器将符号表示的输入序列$(x_1,…,x_n)$ 映射到连续表示序列$z =(z_1,…,z_n)$。 给定z,解码器一次一个元素地生成输出序列$(y_1,…,y_m)$。 在每个步骤中,模型是自动回归的,在生成下一个字符时会利用之前生成的符号作为附加输入。
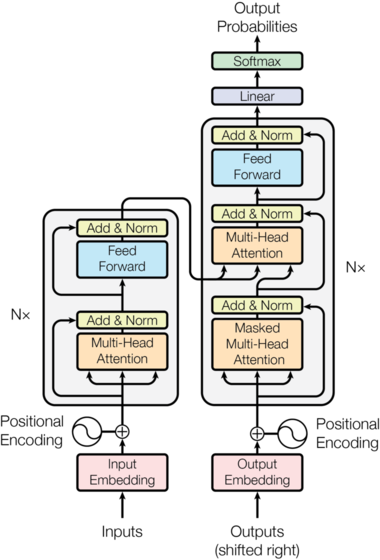
模型整体结构如下:
数据预处理
和之前博文中实现的模型一样。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
import torchtext
from torchtext.datasets import TranslationDataset, Multi30k
from torchtext.data import Field, BucketIterator
import spacy
import random
import math
import os
import time
SEED = 1
random.seed(SEED)
torch.manual_seed(SEED)
torch.backends.cudnn.deterministic = True
spacy_de = spacy.load('de')
spacy_en = spacy.load('en')
def tokenize_de(text):
"""
Tokenizes German text from a string into a list of strings
"""
return [tok.text for tok in spacy_de.tokenizer(text)]
def tokenize_en(text):
"""
Tokenizes English text from a string into a list of strings
"""
return [tok.text for tok in spacy_en.tokenizer(text)]
SRC = Field(tokenize=tokenize_de, init_token='<sos>', eos_token='<eos>', lower=True, batch_first=True) # batch_first=True ---> [batch_size,sequence_length]
TRG = Field(tokenize=tokenize_en, init_token='<sos>', eos_token='<eos>', lower=True, batch_first=True)
train_data, valid_data, test_data = Multi30k.splits(exts=('.de', '.en'), fields=(SRC, TRG))
SRC.build_vocab(train_data, min_freq=2)
TRG.build_vocab(train_data, min_freq=2)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
BATCH_SIZE = 128
train_iterator, valid_iterator, test_iterator = BucketIterator.splits(
(train_data, valid_data, test_data),
batch_size=BATCH_SIZE,
device=device)
Encoder
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
class Encoder(nn.Module):
def __init__(self, input_dim, hid_dim, n_layers, n_heads, pf_dim, encoder_layer, self_attention, positionwise_feedforward, dropout, device):
super().__init__()
self.input_dim = input_dim
self.hid_dim = hid_dim
self.n_layers = n_layers
self.n_heads = n_heads
self.pf_dim = pf_dim
self.encoder_layer = encoder_layer
self.self_attention = self_attention
self.positionwise_feedforward = positionwise_feedforward
self.dropout = dropout
self.device = device
self.tok_embedding = nn.Embedding(input_dim, hid_dim)
self.pos_embedding = nn.Embedding(1000, hid_dim)
self.layers = nn.ModuleList([encoder_layer(hid_dim, n_heads, pf_dim, self_attention, positionwise_feedforward, dropout, device)
for _ in range(n_layers)])
self.do = nn.Dropout(dropout)
self.scale = torch.sqrt(torch.FloatTensor([hid_dim])).to(device)
def forward(self, src, src_mask):
#src = [batch size, src sent len]
#src_mask = [batch size, src sent len]
pos = torch.arange(0, src.shape[1]).unsqueeze(0).repeat(src.shape[0], 1).to(self.device)
src = self.do((self.tok_embedding(src) * self.scale) + self.pos_embedding(pos))
#src = [batch size, src sent len, hid dim]
for layer in self.layers:
src = layer(src, src_mask)
return src
Encoder layer
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
class EncoderLayer(nn.Module):
def __init__(self, hid_dim, n_heads, pf_dim, self_attention, positionwise_feedforward, dropout, device):
super().__init__()
self.ln = nn.LayerNorm(hid_dim)
self.sa = self_attention(hid_dim, n_heads, dropout, device)
self.pf = positionwise_feedforward(hid_dim, pf_dim, dropout)
self.do = nn.Dropout(dropout)
def forward(self, src, src_mask):
#src = [batch size, src sent len, hid dim]
#src_mask = [batch size, src sent len]
src = self.ln(src + self.do(self.sa(src, src, src, src_mask)))
src = self.ln(src + self.do(self.pf(src)))
return src
self-attention
Multi-Head Attention相当于 h 个不同的self-attention的集成(ensemble),在这里我们以 h=8 举例说明。Multi-Head Attention的输出分成3步: 将数据 X 分别输入到图13所示的8个self-attention中,得到8个加权后的特征矩阵$ Z_i, i\in{1,2,…,8} $。 将8个$ Z_i $ 按列拼成一个大的特征矩阵; 特征矩阵经过一层全连接后得到输出 Z 。 整个过程如图14所示:
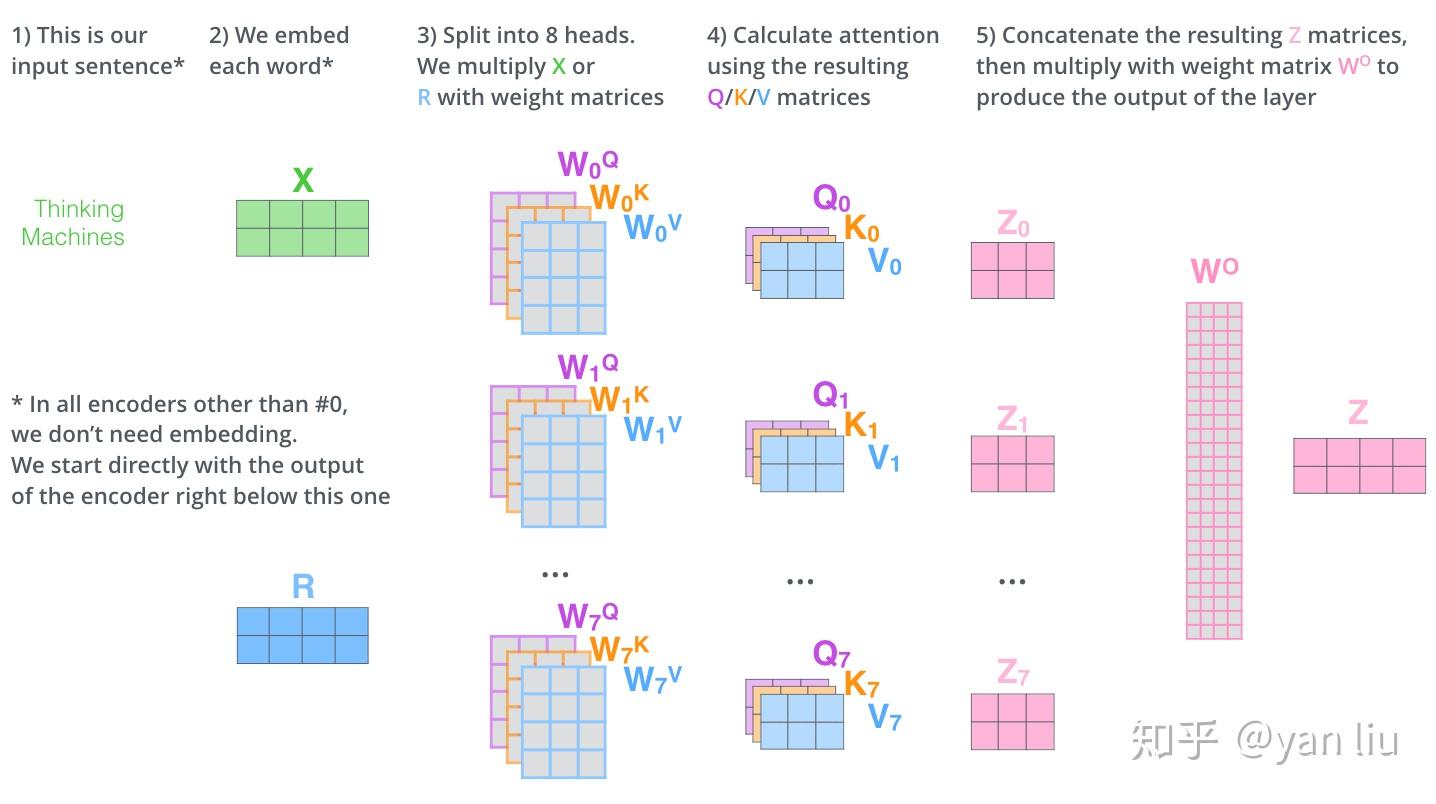
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
class SelfAttention(nn.Module):
def __init__(self, hid_dim, n_heads, dropout, device):
super().__init__()
self.hid_dim = hid_dim
self.n_heads = n_heads
assert hid_dim % n_heads == 0
self.w_q = nn.Linear(hid_dim, hid_dim)
self.w_k = nn.Linear(hid_dim, hid_dim)
self.w_v = nn.Linear(hid_dim, hid_dim)
self.fc = nn.Linear(hid_dim, hid_dim)
self.do = nn.Dropout(dropout)
self.scale = torch.sqrt(torch.FloatTensor([hid_dim // n_heads])).to(device)
def forward(self, query, key, value, mask=None):
bsz = query.shape[0]
#query = key = value [batch size, sent len, hid dim]
Q = self.w_q(query)
K = self.w_k(key)
V = self.w_v(value)
#Q, K, V = [batch size, sent len, hid dim]
Q = Q.view(bsz, -1, self.n_heads, self.hid_dim // self.n_heads).permute(0, 2, 1, 3)
K = K.view(bsz, -1, self.n_heads, self.hid_dim // self.n_heads).permute(0, 2, 1, 3)
V = V.view(bsz, -1, self.n_heads, self.hid_dim // self.n_heads).permute(0, 2, 1, 3)
#Q, K, V = [batch size, n heads, sent len, hid dim // n heads]
energy = torch.matmul(Q, K.permute(0, 1, 3, 2)) / self.scale
#energy = [batch size, n heads, sent len, sent len]
if mask is not None:
energy = energy.masked_fill(mask == 0, -1e10)
attention = self.do(F.softmax(energy, dim=-1))
#attention = [batch size, n heads, sent len, sent len]
x = torch.matmul(attention, V)
#x = [batch size, n heads, sent len, hid dim // n heads]
x = x.permute(0, 2, 1, 3).contiguous()
#x = [batch size, sent len, n heads, hid dim // n heads]
x = x.view(bsz, -1, self.n_heads * (self.hid_dim // self.n_heads))
#x = [batch size, src sent len, hid dim]
x = self.fc(x)
#x = [batch size, sent len, hid dim]
return x
positionwise-feedforward
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
class PositionwiseFeedforward(nn.Module):
def __init__(self, hid_dim, pf_dim, dropout):
super().__init__()
self.hid_dim = hid_dim
self.pf_dim = pf_dim
self.fc_1 = nn.Conv1d(hid_dim, pf_dim, 1) # convolution neural units
self.fc_2 = nn.Conv1d(pf_dim, hid_dim, 1) # convolution neural units
self.do = nn.Dropout(dropout)
def forward(self, x):
#x = [batch size, sent len, hid dim]
x = x.permute(0, 2, 1)
#x = [batch size, hid dim, sent len]
x = self.do(F.relu(self.fc_1(x)))
#x = [batch size, pf dim, sent len]
x = self.fc_2(x)
#x = [batch size, hid dim, sent len]
x = x.permute(0, 2, 1)
#x = [batch size, sent len, hid dim]
return x
Decoder
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
class Decoder(nn.Module):
def __init__(self, output_dim, hid_dim, n_layers, n_heads, pf_dim, decoder_layer, self_attention, positionwise_feedforward, dropout, device):
super().__init__()
self.output_dim = output_dim
self.hid_dim = hid_dim
self.n_layers = n_layers
self.n_heads = n_heads
self.pf_dim = pf_dim
self.decoder_layer = decoder_layer
self.self_attention = self_attention
self.positionwise_feedforward = positionwise_feedforward
self.dropout = dropout
self.device = device
self.tok_embedding = nn.Embedding(output_dim, hid_dim)
self.pos_embedding = nn.Embedding(1000, hid_dim)
self.layers = nn.ModuleList([decoder_layer(hid_dim, n_heads, pf_dim, self_attention, positionwise_feedforward, dropout, device)
for _ in range(n_layers)])
self.fc = nn.Linear(hid_dim, output_dim)
self.do = nn.Dropout(dropout)
self.scale = torch.sqrt(torch.FloatTensor([hid_dim])).to(device)
def forward(self, trg, src, trg_mask, src_mask):
#trg = [batch_size, trg sent len]
#src = [batch_size, src sent len, hid_dim] # encoder output
#trg_mask = [batch size, trg sent len]
#src_mask = [batch size, src sent len]
pos = torch.arange(0, trg.shape[1]).unsqueeze(0).repeat(trg.shape[0], 1).to(self.device)
trg = self.do((self.tok_embedding(trg) * self.scale) + self.pos_embedding(pos))
#trg = [batch size, trg sent len, hid dim]
for layer in self.layers:
trg = layer(trg, src, trg_mask, src_mask)
return self.fc(trg)
Decoder layer
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
class DecoderLayer(nn.Module):
def __init__(self, hid_dim, n_heads, pf_dim, self_attention, positionwise_feedforward, dropout, device):
super().__init__()
self.ln = nn.LayerNorm(hid_dim)
self.sa = self_attention(hid_dim, n_heads, dropout, device)
self.ea = self_attention(hid_dim, n_heads, dropout, device)
self.pf = positionwise_feedforward(hid_dim, pf_dim, dropout)
self.do = nn.Dropout(dropout)
def forward(self, trg, src, trg_mask, src_mask):
#trg = [batch size, trg sent len, hid dim]
#src = [batch size, src sent len, hid dim]
#trg_mask = [batch size, trg sent len]
#src_mask = [batch size, src sent len]
trg = self.ln(trg + self.do(self.sa(trg, trg, trg, trg_mask)))
trg = self.ln(trg + self.do(self.ea(trg, src, src, src_mask)))
trg = self.ln(trg + self.do(self.pf(trg)))
return trg
transformer
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
class Seq2Seq(nn.Module):
def __init__(self, encoder, decoder, pad_idx, device):
super().__init__()
self.encoder = encoder
self.decoder = decoder
self.pad_idx = pad_idx
self.device = device
def make_masks(self, src, trg):
#src = [batch size, src sent len]
#trg = [batch size, trg sent len]
src_mask = (src != self.pad_idx).unsqueeze(1).unsqueeze(2)
trg_pad_mask = (trg != self.pad_idx).unsqueeze(1).unsqueeze(3)
trg_len = trg.shape[1]
trg_sub_mask = torch.tril(torch.ones((trg_len, trg_len), dtype=torch.uint8, device=self.device))
trg_mask = trg_pad_mask & trg_sub_mask
return src_mask, trg_mask
def forward(self, src, trg):
#src = [batch size, src sent len]
#trg = [batch size, trg sent len]
src_mask, trg_mask = self.make_masks(src, trg)
enc_src = self.encoder(src, src_mask)
#enc_src = [batch size, src sent len, hid dim]
out = self.decoder(trg, enc_src, trg_mask, src_mask)
#out = [batch size, trg sent len, output dim]
return out
实例化模型
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
input_dim = len(SRC.vocab)
hid_dim = 512
n_layers = 6
n_heads = 8
pf_dim = 2048
dropout = 0.1
enc = Encoder(input_dim, hid_dim, n_layers, n_heads, pf_dim, EncoderLayer, SelfAttention, PositionwiseFeedforward, dropout, device)
output_dim = len(TRG.vocab)
hid_dim = 512
n_layers = 6
n_heads = 8
pf_dim = 2048
dropout = 0.1
dec = Decoder(output_dim, hid_dim, n_layers, n_heads, pf_dim, DecoderLayer, SelfAttention, PositionwiseFeedforward, dropout, device)
pad_idx = SRC.vocab.stoi['<pad>']
model = Seq2Seq(enc, dec, pad_idx, device).to(device)
初始化参数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
for p in model.parameters():
if p.dim() > 1:
nn.init.xavier_uniform_(p)
class NoamOpt:
"Optim wrapper that implements rate."
def __init__(self, model_size, factor, warmup, optimizer):
self.optimizer = optimizer
self._step = 0
self.warmup = warmup
self.factor = factor
self.model_size = model_size
self._rate = 0
def step(self):
"Update parameters and rate"
self._step += 1
rate = self.rate()
for p in self.optimizer.param_groups:
p['lr'] = rate
self._rate = rate
self.optimizer.step()
def rate(self, step = None):
"Implement `lrate` above"
if step is None:
step = self._step
return self.factor * (self.model_size ** (-0.5) * min(step ** (-0.5), step * self.warmup ** (-1.5)))
optimizer = NoamOpt(hid_dim, 1, 2000,
torch.optim.Adam(model.parameters(), lr=0, betas=(0.9, 0.98), eps=1e-9))
criterion = nn.CrossEntropyLoss(ignore_index=pad_idx)
训练和评估模型
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
def train(model, iterator, optimizer, criterion, clip):
model.train()
epoch_loss = 0
for i, batch in enumerate(iterator):
src = batch.src
trg = batch.trg
optimizer.optimizer.zero_grad()
output = model(src, trg[:,:-1])
#output = [batch size, trg sent len - 1, output dim]
#trg = [batch size, trg sent len]
output = output.contiguous().view(-1, output.shape[-1])
trg = trg[:,1:].contiguous().view(-1)
#output = [batch size * trg sent len - 1, output dim]
#trg = [batch size * trg sent len - 1]
loss = criterion(output, trg)
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), clip)
optimizer.step()
epoch_loss += loss.item()
return epoch_loss / len(iterator)
def evaluate(model, iterator, criterion):
model.eval()
epoch_loss = 0
with torch.no_grad():
for i, batch in enumerate(iterator):
src = batch.src
trg = batch.trg
output = model(src, trg[:,:-1])
#output = [batch size, trg sent len - 1, output dim]
#trg = [batch size, trg sent len]
output = output.contiguous().view(-1, output.shape[-1])
trg = trg[:,1:].contiguous().view(-1)
#output = [batch size * trg sent len - 1, output dim]
#trg = [batch size * trg sent len - 1]
loss = criterion(output, trg)
epoch_loss += loss.item()
return epoch_loss / len(iterator)
def epoch_time(start_time, end_time):
elapsed_time = end_time - start_time
elapsed_mins = int(elapsed_time / 60)
elapsed_secs = int(elapsed_time - (elapsed_mins * 60))
return elapsed_mins, elapsed_secs
N_EPOCHS = 10
CLIP = 1
SAVE_DIR = 'models'
MODEL_SAVE_PATH = os.path.join(SAVE_DIR, 'transformer-seq2seq.pt')
best_valid_loss = float('inf')
if not os.path.isdir(f'{SAVE_DIR}'):
os.makedirs(f'{SAVE_DIR}')
for epoch in range(N_EPOCHS):
start_time = time.time()
train_loss = train(model, train_iterator, optimizer, criterion, CLIP)
valid_loss = evaluate(model, valid_iterator, criterion)
end_time = time.time()
epoch_mins, epoch_secs = epoch_time(start_time, end_time)
if valid_loss < best_valid_loss:
best_valid_loss = valid_loss
torch.save(model.state_dict(), MODEL_SAVE_PATH)
print(f'| Epoch: {epoch+1:03} | Time: {epoch_mins}m {epoch_secs}s| Train Loss: {train_loss:.3f} | Train PPL: {math.exp(train_loss):7.3f} | Val. Loss: {valid_loss:.3f} | Val. PPL: {math.exp(valid_loss):7.3f} |')
训练结果:
1
2
3
4
5
6
7
8
9
10
| Epoch: 001 | Time: 0m 53s| Train Loss: 5.947 | Train PPL: 382.509 | Val. Loss: 4.110 | Val. PPL: 60.939 |
| Epoch: 002 | Time: 0m 53s| Train Loss: 3.772 | Train PPL: 43.474 | Val. Loss: 3.196 | Val. PPL: 24.446 |
| Epoch: 003 | Time: 0m 53s| Train Loss: 3.127 | Train PPL: 22.811 | Val. Loss: 2.806 | Val. PPL: 16.538 |
| Epoch: 004 | Time: 0m 54s| Train Loss: 2.762 | Train PPL: 15.824 | Val. Loss: 2.570 | Val. PPL: 13.060 |
| Epoch: 005 | Time: 0m 53s| Train Loss: 2.507 | Train PPL: 12.263 | Val. Loss: 2.413 | Val. PPL: 11.162 |
| Epoch: 006 | Time: 0m 53s| Train Loss: 2.313 | Train PPL: 10.104 | Val. Loss: 2.323 | Val. PPL: 10.209 |
| Epoch: 007 | Time: 0m 54s| Train Loss: 2.186 | Train PPL: 8.901 | Val. Loss: 2.310 | Val. PPL: 10.072 |
| Epoch: 008 | Time: 0m 53s| Train Loss: 2.103 | Train PPL: 8.191 | Val. Loss: 2.283 | Val. PPL: 9.807 |
| Epoch: 009 | Time: 0m 53s| Train Loss: 2.057 | Train PPL: 7.820 | Val. Loss: 2.307 | Val. PPL: 10.043 |
| Epoch: 010 | Time: 0m 52s| Train Loss: 2.003 | Train PPL: 7.408 | Val. Loss: 2.285 | Val. PPL: 9.823 |
测试结果:
1
2
3
4
5
model.load_state_dict(torch.load(MODEL_SAVE_PATH))
test_loss = evaluate(model, test_iterator, criterion)
print(f'| Test Loss: {test_loss:.3f} | Test PPL: {math.exp(test_loss):7.3f} |')
1
| Test Loss: 2.281 | Test PPL: 9.791 |
总结
优点:(1)虽然Transformer最终也没有逃脱传统学习的套路,Transformer也只是一个全连接(或者是一维卷积)加Attention的结合体。但是其设计已经足够有创新,因为其抛弃了在NLP中最根本的RNN或者CNN并且取得了非常不错的效果,算法的设计非常精彩,值得每个深度学习的相关人员仔细研究和品位。(2)Transformer的设计最大的带来性能提升的关键是将任意两个单词的距离是1,这对解决NLP中棘手的长期依赖问题是非常有效的。(3)Transformer不仅仅可以应用在NLP的机器翻译领域,甚至可以不局限于NLP领域,是非常有科研潜力的一个方向。(4)算法的并行性非常好,符合目前的硬件(主要指GPU)环境。
缺点:(1)粗暴的抛弃RNN和CNN虽然非常炫技,但是它也使模型丧失了捕捉局部特征的能力,RNN + CNN + Transformer的结合可能会带来更好的效果。(2)Transformer失去的位置信息其实在NLP中非常重要,而论文中在特征向量中加入Position Embedding也只是一个权宜之计,并没有改变Transformer结构上的固有缺陷。