5 - Convolutional Sequence to Sequence Learning
数据预处理
数据预处理与前面几个模型不同的是在声明field类时,将batch_first参数设置为True,则返回的batch维度是[batch_size,sequence_length];若batch_first设置为False,则返回的batch维度是[sequence_length,batch_size]。(默认值为False)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
import torchtext
from torchtext.datasets import TranslationDataset, Multi30k
from torchtext.data import Field, BucketIterator
import spacy
import random
import math
import os
import time
SEED = 1
random.seed(SEED)
torch.manual_seed(SEED)
torch.backends.cudnn.deterministic = True
spacy_de = spacy.load('de')
spacy_en = spacy.load('en')
def tokenize_de(text):
"""
Tokenizes German text from a string into a list of strings
"""
return [tok.text for tok in spacy_de.tokenizer(text)]
def tokenize_en(text):
"""
Tokenizes English text from a string into a list of strings
"""
return [tok.text for tok in spacy_en.tokenizer(text)]
SRC = Field(tokenize=tokenize_de, init_token='<sos>', eos_token='<eos>', lower=True, batch_first=True) # batch_first=True ---> [batch_size,sequence_length]
TRG = Field(tokenize=tokenize_en, init_token='<sos>', eos_token='<eos>', lower=True, batch_first=True)
train_data, valid_data, test_data = Multi30k.splits(exts=('.de', '.en'), fields=(SRC, TRG))
SRC.build_vocab(train_data, min_freq=2)
TRG.build_vocab(train_data, min_freq=2)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
BATCH_SIZE = 128
train_iterator, valid_iterator, test_iterator = BucketIterator.splits(
(train_data, valid_data, test_data),
batch_size=BATCH_SIZE,
device=device)
Encoder
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
class Encoder(nn.Module):
def __init__(self, input_dim, emb_dim, hid_dim, n_layers, kernel_size, dropout, device):
super().__init__()
assert kernel_size % 2 == 1, "Kernel size must be odd (for now)"
self.input_dim = input_dim
self.emb_dim = emb_dim
self.hid_dim = hid_dim
self.kernel_size = kernel_size
self.dropout = dropout
self.device = device
self.scale = torch.sqrt(torch.FloatTensor([0.5])).to(device)
self.tok_embedding = nn.Embedding(input_dim, emb_dim) # word embedding
self.pos_embedding = nn.Embedding(1000, emb_dim) # postion embedding
self.emb2hid = nn.Linear(emb_dim, hid_dim)
self.hid2emb = nn.Linear(hid_dim, emb_dim)
self.convs = nn.ModuleList([nn.Conv1d(hid_dim, 2*hid_dim, kernel_size, padding=(kernel_size-1)//2) for _ in range(n_layers)]) # convolutional layers
self.dropout = nn.Dropout(dropout)
def forward(self, src):
#src = [batch size, src sent len]
#create position tensor
pos = torch.arange(0, src.shape[1]).unsqueeze(0).repeat(src.shape[0], 1).to(self.device)
#pos = [batch size, src sent len]
#embed tokens and positions
tok_embedded = self.tok_embedding(src)
pos_embedded = self.pos_embedding(pos)
#tok_embedded = pos_embedded= [batch size, src sent len, emb dim]
#combine embeddings by elementwise summing
embedded = self.dropout(tok_embedded + pos_embedded)
#embedded = [batch size, src sent len, emb dim]
#pass embedded through linear layer to go through emb dim -> hid dim
conv_input = self.emb2hid(embedded)
#conv_input = [batch size, src sent len, hid dim]
#permute for convolutional layer
conv_input = conv_input.permute(0, 2, 1)
#conv_input = [batch size, hid dim, src sent len]
#nn.conv1d里面的in_channels的维度 = input矩阵倒数第二个维度!!!
for i, conv in enumerate(self.convs):
#pass through convolutional layer
conved = conv(self.dropout(conv_input))
#conved = [batch size, 2*hid dim, src sent len]
#pass through GLU activation function
conved = F.glu(conved, dim=1)
#conved = [batch size, hid dim, src sent len]
#apply residual connection
conved = (conved + conv_input) * self.scale
#conved = [batch size, hid dim, src sent len]
#set conv_input to conved for next loop iteration
conv_input = conved
#permute and convert back to emb dim
conved = self.hid2emb(conved.permute(0, 2, 1))
#conved = [batch size, src sent len, emb dim]
#elementwise sum output (conved) and input (embedded) to be used for attention
combined = (conved + embedded) * self.scale
#combined = [batch size, src sent len, emb dim]
return conved, combined
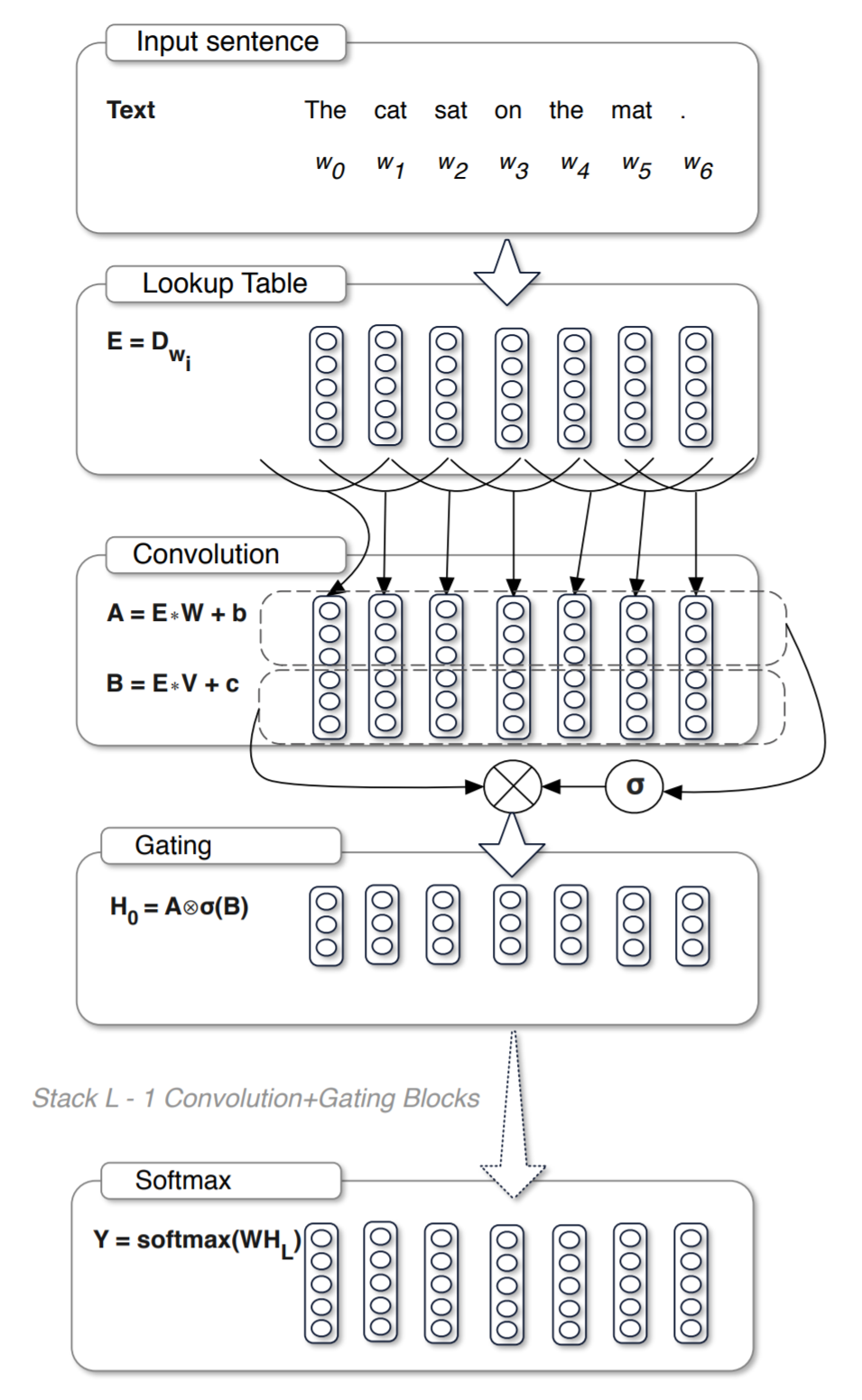
torch.nn.functional.glu是Gated Convolutional Networks里面的一种算法——Gated Linear Units (GLU),公式如下:
where input is split in half along dim to form A and B.
Gated Convolutional Networks的架构如下图:
Decoder
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
class Decoder(nn.Module):
def __init__(self, output_dim, emb_dim, hid_dim, n_layers, kernel_size, dropout, pad_idx, device):
super().__init__()
self.output_dim = output_dim
self.emb_dim = emb_dim
self.hid_dim = hid_dim
self.kernel_size = kernel_size
self.dropout = dropout
self.pad_idx = pad_idx
self.device = device
self.scale = torch.sqrt(torch.FloatTensor([0.5])).to(device)
self.tok_embedding = nn.Embedding(output_dim, emb_dim)
self.pos_embedding = nn.Embedding(1000, emb_dim)
self.emb2hid = nn.Linear(emb_dim, hid_dim)
self.hid2emb = nn.Linear(hid_dim, emb_dim)
self.attn_hid2emb = nn.Linear(hid_dim, emb_dim)
self.attn_emb2hid = nn.Linear(emb_dim, hid_dim)
self.out = nn.Linear(emb_dim, output_dim)
self.convs = nn.ModuleList([nn.Conv1d(hid_dim, 2*hid_dim, kernel_size)
for _ in range(n_layers)])
self.dropout = nn.Dropout(dropout)
def calculate_attention(self, embedded, conved, encoder_conved, encoder_combined):
#embedded = [batch size, trg sent len, emb dim]
#conved = [batch size, hid dim, trg sent len]
#encoder_conved = encoder_combined = [batch size, src sent len, emb dim]
#permute and convert back to emb dim
conved_emb = self.attn_hid2emb(conved.permute(0, 2, 1))
#conved_emb = [batch size, trg sent len, emb dim]
combined = (embedded + conved_emb) * self.scale
#combined = [batch size, trg sent len, emb dim]
energy = torch.matmul(combined, encoder_conved.permute(0, 2, 1))
#energy = [batch size, trg sent len, src sent len]
attention = F.softmax(energy, dim=2)
#attention = [batch size, trg sent len, src sent len]
attended_encoding = torch.matmul(attention, (encoder_conved + encoder_combined))
#attended_encoding = [batch size, trg sent len, emd dim]
#convert from emb dim -> hid dim
attended_encoding = self.attn_emb2hid(attended_encoding)
#attended_encoding = [batch size, trg sent len, hid dim]
attended_combined = (conved + attended_encoding.permute(0, 2, 1)) * self.scale
#attended_combined = [batch size, hid dim, trg sent len]
return attention, attended_combined
def forward(self, trg, encoder_conved, encoder_combined):
#trg = [batch size, trg sent len]
#encoder_conved = encoder_combined = [batch size, src sent len, emb dim]
#create position tensor
pos = torch.arange(0, trg.shape[1]).unsqueeze(0).repeat(trg.shape[0], 1).to(device)
#pos = [batch size, trg sent len]
#embed tokens and positions
tok_embedded = self.tok_embedding(trg)
pos_embedded = self.pos_embedding(pos)
#tok_embedded = [batch size, trg sent len, emb dim]
#pos_embedded = [batch size, trg sent len, emb dim]
#combine embeddings by elementwise summing
embedded = self.dropout(tok_embedded + pos_embedded)
#embedded = [batch size, trg sent len, emb dim]
#pass embedded through linear layer to go through emb dim -> hid dim
conv_input = self.emb2hid(embedded)
#conv_input = [batch size, trg sent len, hid dim]
#permute for convolutional layer
conv_input = conv_input.permute(0, 2, 1)
#conv_input = [batch size, hid dim, trg sent len]
for i, conv in enumerate(self.convs):
#apply dropout
conv_input = self.dropout(conv_input)
#need to pad so decoder can't "cheat"
padding = torch.zeros(conv_input.shape[0], conv_input.shape[1], self.kernel_size-1).fill_(self.pad_idx).to(device)
padded_conv_input = torch.cat((padding, conv_input), dim=2)
#padded_conv_input = [batch size, hid dim, trg sent len + kernel size - 1]
#pass through convolutional layer
conved = conv(padded_conv_input)
#conved = [batch size, 2*hid dim, trg sent len]
#pass through GLU activation function
conved = F.glu(conved, dim=1)
#conved = [batch size, hid dim, trg sent len]
attention, conved = self.calculate_attention(embedded, conved, encoder_conved, encoder_combined)
#attention = [batch size, trg sent len, src sent len]
#conved = [batch size, hid dim, trg sent len]
#apply residual connection
conved = (conved + conv_input) * self.scale
#conved = [batch size, hid dim, trg sent len]
#set conv_input to conved for next loop iteration
conv_input = conved
conved = self.hid2emb(conved.permute(0, 2, 1))
#conved = [batch size, trg sent len, hid dim]
output = self.out(self.dropout(conved))
#output = [batch size, trg sent len, output dim]
return output, attention
seq2seq
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
class Seq2Seq(nn.Module):
def __init__(self, encoder, decoder, device):
super().__init__()
self.encoder = encoder
self.decoder = decoder
self.device = device
def forward(self, src, trg):
#src = [batch size, src sent len]
#trg = [batch size, trg sent len]
#calculate z^u (encoder_conved) and e (encoder_combined)
#encoder_conved is output from final encoder conv. block
#encoder_combined is encoder_conved plus (elementwise) src embedding plus positional embeddings
encoder_conved, encoder_combined = self.encoder(src)
#encoder_conved = [batch size, src sent len, emb dim]
#encoder_combined = [batch size, src sent len, emb dim]
#calculate predictions of next words
#output is a batch of predictions for each word in the trg sentence
#attention a batch of attention scores across the src sentence for each word in the trg sentence
output, attention = self.decoder(trg, encoder_conved, encoder_combined)
#output = [batch size, trg sent len, output dim]
#attention = [batch size, trg sent len, src sent len]
return output, attention
训练模型
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
INPUT_DIM = len(SRC.vocab)
OUTPUT_DIM = len(TRG.vocab)
EMB_DIM = 256
HID_DIM = 512
ENC_LAYERS = 10
DEC_LAYERS = 10
ENC_KERNEL_SIZE = 3
DEC_KERNEL_SIZE = 3
ENC_DROPOUT = 0.25
DEC_DROPOUT = 0.25
PAD_IDX = TRG.vocab.stoi['<pad>']
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
enc = Encoder(INPUT_DIM, EMB_DIM, HID_DIM, ENC_LAYERS, ENC_KERNEL_SIZE, ENC_DROPOUT, device)
dec = Decoder(OUTPUT_DIM, EMB_DIM, HID_DIM, DEC_LAYERS, DEC_KERNEL_SIZE, DEC_DROPOUT, PAD_IDX, device)
model = Seq2Seq(enc, dec, device).to(device)
optimizer = optim.Adam(model.parameters())
criterion = nn.CrossEntropyLoss(ignore_index=PAD_IDX)
def train(model, iterator, optimizer, criterion, clip):
model.train()
epoch_loss = 0
for i, batch in enumerate(iterator):
src = batch.src
trg = batch.trg
optimizer.zero_grad()
output, _ = model(src, trg[:,:-1])
#output = [batch size, trg sent len - 1, output dim]
#trg = [batch size, trg sent len]
output = output.contiguous().view(-1, output.shape[-1])
trg = trg[:,1:].contiguous().view(-1)
#output = [batch size * trg sent len - 1, output dim]
#trg = [batch size * trg sent len - 1]
loss = criterion(output, trg)
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), clip)
optimizer.step()
epoch_loss += loss.item()
return epoch_loss / len(iterator)
def evaluate(model, iterator, criterion):
model.eval()
epoch_loss = 0
with torch.no_grad():
for i, batch in enumerate(iterator):
src = batch.src
trg = batch.trg
output, _ = model(src, trg[:,:-1])
#output = [batch size, trg sent len - 1, output dim]
#trg = [batch size, trg sent len]
output = output.contiguous().view(-1, output.shape[-1])
trg = trg[:,1:].contiguous().view(-1)
#output = [batch size * trg sent len - 1, output dim]
#trg = [batch size * trg sent len - 1]
loss = criterion(output, trg)
epoch_loss += loss.item()
return epoch_loss / len(iterator)
def epoch_time(start_time, end_time):
elapsed_time = end_time - start_time
elapsed_mins = int(elapsed_time / 60)
elapsed_secs = int(elapsed_time - (elapsed_mins * 60))
return elapsed_mins, elapsed_secs
N_EPOCHS = 10
CLIP = 1
SAVE_DIR = 'models'
MODEL_SAVE_PATH = os.path.join(SAVE_DIR, 'tut5_model.pt')
best_valid_loss = float('inf')
if not os.path.isdir(f'{SAVE_DIR}'):
os.makedirs(f'{SAVE_DIR}')
for epoch in range(N_EPOCHS):
start_time = time.time()
train_loss = train(model, train_iterator, optimizer, criterion, CLIP)
valid_loss = evaluate(model, valid_iterator, criterion)
end_time = time.time()
epoch_mins, epoch_secs = epoch_time(start_time, end_time)
if valid_loss < best_valid_loss:
best_valid_loss = valid_loss
torch.save(model.state_dict(), MODEL_SAVE_PATH)
print(f'| Epoch: {epoch+1:03} | Time: {epoch_mins}m {epoch_secs}s| Train Loss: {train_loss:.3f} | Train PPL: {math.exp(train_loss):7.3f} | Val. Loss: {valid_loss:.3f} | Val. PPL: {math.exp(valid_loss):7.3f} |')
训练结果:
1
2
3
4
5
6
7
8
9
10
| Epoch: 001 | Time: 0m 30s| Train Loss: 4.081 | Train PPL: 59.203 | Val. Loss: 2.910 | Val. PPL: 18.360 |
| Epoch: 002 | Time: 0m 31s| Train Loss: 2.922 | Train PPL: 18.583 | Val. Loss: 2.354 | Val. PPL: 10.532 |
| Epoch: 003 | Time: 0m 31s| Train Loss: 2.547 | Train PPL: 12.764 | Val. Loss: 2.123 | Val. PPL: 8.359 |
| Epoch: 004 | Time: 0m 30s| Train Loss: 2.328 | Train PPL: 10.260 | Val. Loss: 2.007 | Val. PPL: 7.437 |
| Epoch: 005 | Time: 0m 30s| Train Loss: 2.185 | Train PPL: 8.894 | Val. Loss: 1.921 | Val. PPL: 6.830 |
| Epoch: 006 | Time: 0m 30s| Train Loss: 2.077 | Train PPL: 7.981 | Val. Loss: 1.873 | Val. PPL: 6.507 |
| Epoch: 007 | Time: 0m 30s| Train Loss: 1.990 | Train PPL: 7.319 | Val. Loss: 1.849 | Val. PPL: 6.355 |
| Epoch: 008 | Time: 0m 30s| Train Loss: 1.925 | Train PPL: 6.857 | Val. Loss: 1.815 | Val. PPL: 6.142 |
| Epoch: 009 | Time: 0m 31s| Train Loss: 1.869 | Train PPL: 6.479 | Val. Loss: 1.790 | Val. PPL: 5.991 |
| Epoch: 010 | Time: 0m 30s| Train Loss: 1.821 | Train PPL: 6.178 | Val. Loss: 1.760 | Val. PPL: 5.812 |
测试模型
1
2
3
4
5
model.load_state_dict(torch.load(MODEL_SAVE_PATH))
test_loss = evaluate(model, test_iterator, criterion)
print(f'| Test Loss: {test_loss:.3f} | Test PPL: {math.exp(test_loss):7.3f} |')
测试结果:
1
| Test Loss: 1.846 | Test PPL: 6.332 |
PPL——困惑度
在得到不同的语言模型(一元语言模型、二元语言模型….)的时候,我们如何判断一个语言模型是否好还是坏,一般有两种方法:
1、一种方法将其应用到具体的问题当中,比如机器翻译、speech recognition、spelling corrector等。然后看这个语言模型在这些任务中的表现(extrinsic evaluation,or in-vivo evaluation)。但是,这种方法一方面难以操作,另一方面可能非常耗时,可能跑一个evaluation需要大量时间,费时难操作。
2、针对第一种方法的缺点,大家想是否可以根据与语言模型自身的一些特性,来设计一种简单易行,而又行之有效的评测指标。于是,人们就发明了perplexity这个指标。
困惑度(perplexity)的基本思想是:给测试集的句子赋予较高概率值的语言模型较好,当语言模型训练完之后,测试集中的句子都是正常的句子,那么训练好的模型就是在测试集上的概率越高越好,公式如下:
由公式可知,句子概率越大,语言模型越好,困惑度越小。
模型比较
基于卷积神经网络的模型比之前的使用循环神经网络的模型的困惑度都低,效果更好,并且运算时间节省了一半!!