Torchtext 详细介绍
如果你曾经做过NLP的深度学习项目你就会知道预处理是有多么的痛苦和乏味。在你训练你的模型之前你必须做以下几步:
-
从磁盘读取数据
-
对文本分词
-
给每一个单词创建唯一整数标识
-
把文本转化成整数序列
-
按照你的深度学习框架要求的形式载入数据
-
把所有序列pad成相同的长度,这样你才能以batch的形式处理它们
Torchtext 这个库可以让上面的这些处理变得更加方便。尽管这个库还比较新,但它使用起来非常方便——尤其在批处理和数据载入方面——这让torchtext非常值得去学习。
1. 概述
Torchtext遵循以下的基本方式把数据转化成你的神经网络可以使用的输入形式:
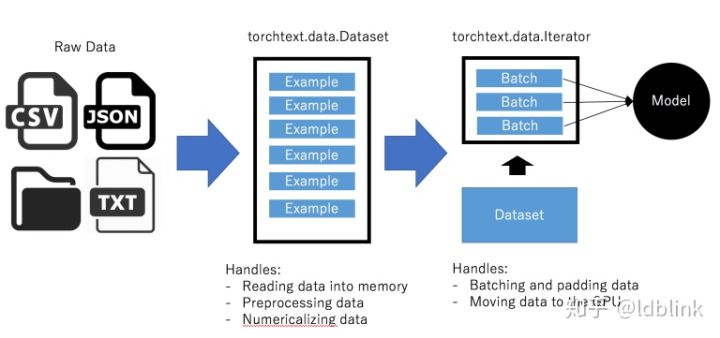
Torchtext从txt文件、csv/tsv文件、json文件和某一目录中(到现在为止有这么多种)读取原始数据,并将它们转换为Datasets。Datasets仅仅是预处理的数据块,通过各种字段(fields)读入内存。它们是其他数据结构可以使用的处理数据的标准形式。
然后torchtext将数据集传递给iterator(迭代器)。迭代器处理数字化,批处理,打包以及将数据移动到GPU。 基本上,它把将数据传递给神经网络的过程中所有繁重的工作都做了。
在下面的章节中,我们将看到这些过程在实际工作示例中是如何实现的。
2. 声明字段-Field
Torchtext采用声明式方法加载数据:你告诉torchtext你希望数据是什么样的,然后torchtext为你处理。
你要做的是声明一个Field对象。 这个Field对象指定你想要怎么处理某个字段。我们来看一个例子:
1
2
3
4
5
from torchtext.data import Field
tokenize = lambda x: x.split()
TEXT = Field(sequential=True, tokenize=tokenize, lower=True)
LABEL = Field(sequential=False, use_vocab=False)
在恶意评论分类数据集中,有两种字段:评论文本(TEXT)和标签(LABEL)(恶意,严重恶意,淫秽,威胁,侮辱和身份仇恨)。
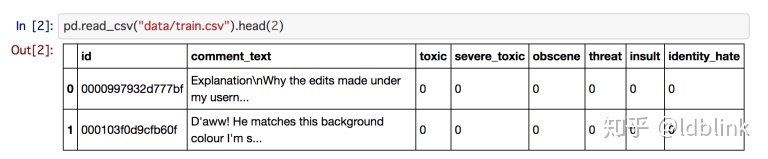
我们首先看一下LABEL字段,因为它更简单。默认情况下,所有字段都需要一系列单词进入,并且期望在后面建立一个从单词到整数的映射(这个映射称为词汇表,我们之后会讲到它是如何被创建的)。如果您传递的字段是默认被数字化的,并且不是顺序序列,则应该传递参数use_vocab = False和sequential = False。
对于评论文本,我们把想对字段做的预处理以传递关键字参数的形式传入。我们给字段一个tokenizer(分词器),告诉它把输入都转换为小写,告诉它输入是顺序序列。
除了上面提到的关键字参数之外,Field类还允许用户指定特殊标记(用于标记词典外词语的unk_token,用于填充的pad_token,用于句子结尾的eos_token以及用于句子开头的可选的init_token)。设置返回值的第一维是batch还是sequence(第一维默认是sequence),并选择是否允许在运行时决定序列长度还是预先就决定好。幸运的是,Field类的文档写得相对较好,所以如果你还需要一些高级的预处理,你可以参考这个文档以获取更多信息。
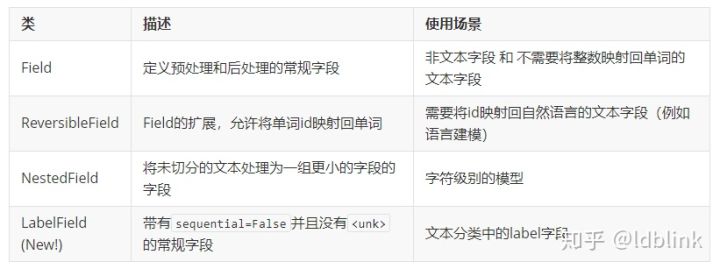
Field类是torchtext的中心,并且使预处理变得更方便。除标准字段类外,当前可用的其他字段(以及它们的用例)列表如下:
3. 构建Dataset
Fields知道怎么处理原始数据,现在我们需要告诉fields去处理哪些数据。这就是我们需要用到Dataset的地方。
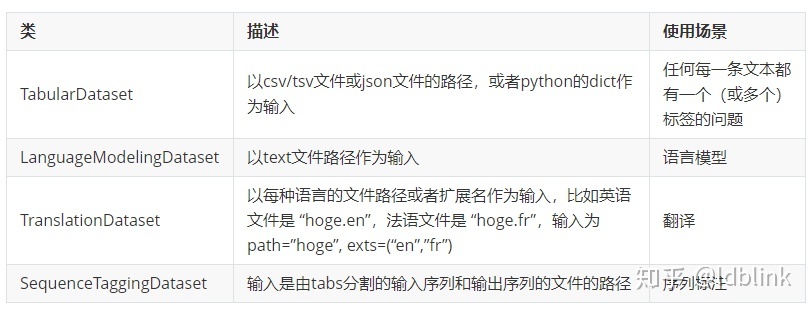
Torchtext中有各种内置Dataset,用于处理常见的数据格式。 对于csv/tsv文件,TabularDataset类很方便。 以下是我们如何使用TabularDataset从csv文件读取数据的示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
from torchtext.data import TabularDataset
tv_datafields = [("id", None), # 我们不会需要id,所以我们传入的filed是None
("comment_text", TEXT), ("toxic", LABEL),
("severe_toxic", LABEL), ("threat", LABEL),
("obscene", LABEL), ("insult", LABEL),
("identity_hate", LABEL)]
trn, vld = TabularDataset.splits(
path="data", # 数据存放的根目录
train='train.csv', validation="valid.csv",
format='csv',
skip_header=True, # 如果你的csv有表头, 确保这个表头不会作为数据处理
fields=tv_datafields)
tst_datafields = [("id", None), # 我们不会需要id,所以我们传入的filed是None
("comment_text", TEXT)]
tst = TabularDataset(
path="data/test.csv", # 文件路径
format='csv',
skip_header=True, # 如果你的csv有表头, 确保这个表头不会作为数据处理
fields=tst_datafields)
对于TabularDataset,我们传入(name,field)对的列表作为fields参数。我们传入的fields必须与列的顺序相同。对于我们不使用的列,我们在fields的位置传入一个None。
splits方法通过应用相同的处理为训练数据和验证数据创建Dataset。 它也可以处理测试数据,但由于测试数据与训练数据和验证数据有不同的格式,因此我们创建了不同的Dataset。
数据集大多可以和list一样去处理。 为了理解这一点,我们看看Dataset内部是怎么样的。 数据集可以像list一样进行索引和迭代,所以让我们看看第一个元素是什么样的:
1
2
3
4
5
6
7
8
>>> trn[0]
<torchtext.data.example.Example at 0x10d3ed3c8>
>>> trn[0].__dict__.keys()
dict_keys(['comment_text', 'toxic', 'severe_toxic', 'threat', 'obscene', 'insult', 'identity_hate'])
>>> trn[0].comment_text[:3]
['explanation', 'why', 'the']
我们得到一个Example类的对象。 Example对象将单个数据的属性放在一起。 我们也看到文本已经被切分,但还没有被转换为整数。因为我们还没有构建从单词到id的映射。我们下一步就来构建这个映射。
Torchtext将单词映射为整数,但必须告诉它应该处理的全部单词。 在我们的例子中,我们可能只想在训练集上建立词汇表,所以我们运行以下代码:
1
TEXT.build_vocab(trn)
这使得torchtext遍历训练集中的所有元素,检查TEXT字段的内容,并将其添加到其词汇表中。Torchtext有自己的Vocab类来处理词汇。Vocab类在stoi属性中包含从word到id的映射,并在其itos属性中包含反向映射。 除此之外,它可以为word2vec等预训练的embedding自动构建embedding矩阵。Vocab类还可以使用像max_size和min_freq这样的选项来表示词汇表中有多少单词或单词出现的次数。未包含在词汇表中的单词将被转换成<unk>。
现在我们已经将数据格式化并读入内存中,下一步是:创建一个迭代器将数据传递给我们的模型。
4. 构建迭代器-iterator
在torchvision和PyTorch中,数据的处理和批处理由DataLoaders处理。 出于某种原因,torchtext相同的东西又命名成了Iterators。 基本功能是一样的,但我们将会看到,Iterators具有一些NLP特有的便捷功能。
以下是如何初始化列车迭代器,验证和测试数据的代码。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
from torchtext.data import Iterator, BucketIterator
train_iter, val_iter = BucketIterator.splits((trn, vld),
# 我们把Iterator希望抽取的Dataset传递进去
batch_sizes=(25, 25),
device=-1,
# 如果要用GPU,这里指定GPU的编号
sort_key=lambda x: len(x.comment_text),
# BucketIterator 依据什么对数据分组
sort_within_batch=False,
repeat=False)
# repeat设置为False,因为我们想要包装这个迭代器层。
test_iter = Iterator(tst, batch_size=64,
device=-1,
sort=False,
sort_within_batch=False,
repeat=False)
sort_within_batch参数设置为True时,按照sort_key按降序对每个小批次内的数据进行排序。当你想对padded序列使用pack_padded_sequence转换为PackedSequence对象时,这是必需的。
BucketIterator是torchtext最强大的功能之一。它会自动将输入序列进行shuffle并做bucket。
这个功能强大的原因是——正如我前面提到的——我们需要填充输入序列使得长度相同才能批处理。 例如,序列
1
2
3
[ [3, 15, 2, 7],
[4, 1],
[5, 5, 6, 8, 1] ]
会需要pad成
1
2
3
[ [3, 15, 2, 7, 0],
[4, 1, 0, 0, 0],
[5, 5, 6, 8, 1] ]
正如你所看到的,填充量由batch中最长的序列决定。因此,当序列长度相似时,填充效率最高。BucketIterator会在在后台执行这些操作。需要注意的是,你需要告诉BucketIterator你想在哪个数据属性上做bucket。在我们的例子中,我们希望根据comment_text字段的长度进行bucket处理,因此我们将其作为关键字参数传入。 有关其他参数的详细信息,请参阅上面的代码。
对于测试数据,我们不想洗牌数据,因为我们将在训练结束时输出预测结果。 这就是我们使用标准迭代器的原因。
以下是torchtext当前实现的iterators器列表:
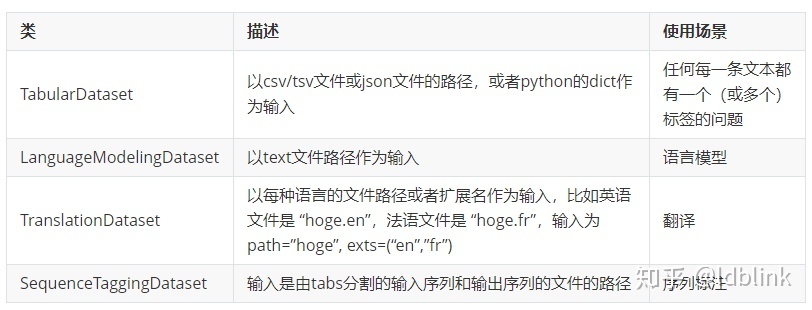
5. 封装迭代器-iterator
目前,迭代器返回一个名为torchtext.data.Batch的自定义数据类型。Batch类具有与Example类相似的API,将来自每个字段的一批数据作为属性。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
>>> batch
[torchtext.data.batch.Batch of size 25]
[.comment_text]:[torch.LongTensor of size 494x25]
[.toxic]:[torch.LongTensor of size 25]
[.severe_toxic]:[torch.LongTensor of size 25]
[.threat]:[torch.LongTensor of size 25]
[.obscene]:[torch.LongTensor of size 25]
[.insult]:[torch.LongTensor of size 25]
[.identity_hate]:[torch.LongTensor of size 25]
>>> batch.__dict__.keys()
dict_keys(['batch_size', 'dataset', 'fields', 'comment_text', 'toxic', 'severe_toxic', 'threat', 'obscene', 'insult', 'identity_hate'])
>>> batch.comment_text
tensor([[ 15, 606, 280, ..., 15, 63, 15],
[ 360, 693, 18, ..., 29, 4, 2],
[ 45, 584, 14, ..., 21, 664, 645],
...,
[ 1, 1, 1, ..., 84, 1, 1],
[ 1, 1, 1, ..., 118, 1, 1],
[ 1, 1, 1, ..., 15, 1, 1]])
>>> batch.toxic
tensor([ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 1, 0, 1, 0, 1, 0, 0, 0, 0])
不幸的是,这种自定义数据类型使得代码重用变得困难(因为每次列名发生变化时,我们都需要修改代码),并且使torchtext在某些情况(如torchsample和fastai)下很难与其他库一起使用。
我希望这可以在未来得到优化(我正在考虑提交PR,如果我可以决定API应该是什么样的话),但同时,我们使用简单的封装来使batch易于使用。
具体来说,我们将把batch转换为形式为(x,y)的元组,其中x是自变量(模型的输入),y是因变量(标签数据)。 代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
class BatchWrapper:
def __init__(self, dl, x_var, y_vars):
self.dl, self.x_var, self.y_vars = dl, x_var, y_vars # 传入自变量x列表和因变量y列表
def __iter__(self):
for batch in self.dl:
x = getattr(batch, self.x_var) # 在这个封装中只有一个自变量
if self.y_vars is not None: # 把所有因变量cat成一个向量
temp = [getattr(batch, feat).unsqueeze(1) for feat in self.y_vars]
y = torch.cat(temp, dim=1).float()
else:
y = torch.zeros((1))
yield (x, y)
def __len__(self):
return len(self.dl)
train_dl = BatchWrapper(train_iter, "comment_text", ["toxic", "severe_toxic", "obscene", "threat", "insult", "identity_hate"])
valid_dl = BatchWrapper(val_iter, "comment_text", ["toxic", "severe_toxic", "obscene", "threat", "insult", "identity_hate"])
test_dl = BatchWrapper(test_iter, "comment_text", None)
我们在这里所做的是将Batch对象转换为输入和输出的元组。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
>>> next(train_dl.__iter__())
(tensor([[ 15, 15, 15, ..., 375, 354, 44],
[ 601, 657, 360, ..., 27, 63, 739],
[ 242, 22, 45, ..., 526, 4, 3],
...,
[ 1, 1, 1, ..., 1, 1, 1],
[ 1, 1, 1, ..., 1, 1, 1],
[ 1, 1, 1, ..., 1, 1, 1]]),
tensor([[ 0., 0., 0., 0., 0., 0.],
[ 0., 0., 0., 0., 0., 0.],
[ 0., 0., 0., 0., 0., 0.],
[ 0., 0., 0., 0., 0., 0.],
[ 1., 0., 0., 0., 0., 0.],
[ 0., 0., 0., 0., 0., 0.],
[ 0., 0., 0., 0., 0., 0.],
[ 0., 0., 0., 0., 0., 0.],
[ 0., 0., 0., 0., 0., 0.],
[ 0., 0., 0., 0., 0., 0.],
[ 0., 0., 0., 0., 0., 0.],
[ 0., 0., 0., 0., 0., 0.],
[ 0., 0., 0., 0., 0., 0.],
[ 0., 0., 0., 0., 0., 0.],
[ 0., 0., 0., 0., 0., 0.],
[ 0., 0., 0., 0., 0., 0.],
[ 0., 0., 0., 0., 0., 0.],
[ 1., 0., 0., 0., 0., 0.],
[ 0., 0., 0., 0., 0., 0.],
[ 0., 0., 0., 0., 0., 0.],
[ 0., 0., 0., 0., 0., 0.],
[ 0., 0., 0., 0., 0., 0.],
[ 0., 0., 0., 0., 0., 0.],
[ 1., 1., 0., 1., 1., 0.],
[ 0., 0., 0., 0., 0., 0.]]))
如果需要深入研究torchtext,可以去阅读它的官方文档.