4 - Packed Padded Sequences, Masking and Inference
数据预处理与模型准备
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
import torchtext
from torchtext.datasets import TranslationDataset, Multi30k
from torchtext.data import Field, BucketIterator
import matplotlib.pyplot as plt
import matplotlib.ticker as ticker
import spacy
import random
import math
import os
SEED = 1
random.seed(SEED)
torch.manual_seed(SEED)
torch.backends.cudnn.deterministic = True
spacy_de = spacy.load('de')
spacy_en = spacy.load('en')
def tokenize_de(text):
"""
Tokenizes German text from a string into a list of strings
"""
return [tok.text for tok in spacy_de.tokenizer(text)]
def tokenize_en(text):
"""
Tokenizes English text from a string into a list of strings
"""
return [tok.text for tok in spacy_en.tokenizer(text)]
- 包括源语句(source input)的长度,
including_lengths=True
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
SRC = Field(tokenize=tokenize_de, init_token='<sos>', eos_token='<eos>', lower=True, include_lengths=True)
TRG = Field(tokenize=tokenize_en, init_token='<sos>', eos_token='<eos>', lower=True)
train_data, valid_data, test_data = Multi30k.splits(exts=('.de', '.en'), fields=(SRC, TRG))
SRC.build_vocab(train_data, min_freq=2)
TRG.build_vocab(train_data, min_freq=2)
BATCH_SIZE = 128
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
train_iterator, valid_iterator, test_iterator = BucketIterator.splits(
(train_data, valid_data, test_data),
batch_size=BATCH_SIZE,
sort_key = lambda x : len(x.src),
sort_within_batch=True,
device=device) # sort sequence by length
- 编码器需要接受源序列的长度
- 在进入RNN之前需要打包序列(pack sequence)
- 在返回之前需要解压缩输出(unpack sequence)
Encoder
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
class Encoder(nn.Module):
def __init__(self, input_dim, emb_dim, enc_hid_dim, dec_hid_dim, dropout):
super().__init__()
self.input_dim = input_dim
self.emb_dim = emb_dim
self.enc_hid_dim = enc_hid_dim
self.dec_hid_dim = dec_hid_dim
self.dropout = dropout
self.embedding = nn.Embedding(input_dim, emb_dim)
self.rnn = nn.GRU(emb_dim, enc_hid_dim, bidirectional=True)
self.fc = nn.Linear(enc_hid_dim * 2, dec_hid_dim)
self.dropout = nn.Dropout(dropout)
def forward(self, src, src_len):
#src = [src sent len, batch size]
#src_len = [src sent len]
embedded = self.dropout(self.embedding(src))
#embedded = [src sent len, batch size, emb dim]
packed_embedded = nn.utils.rnn.pack_padded_sequence(embedded, src_len)
packed_outputs, hidden = self.rnn(packed_embedded)
outputs, _ = nn.utils.rnn.pad_packed_sequence(packed_outputs)
#outputs = [sent len, batch size, hid dim * num directions]
#hidden = [n layers * num directions, batch size, hid dim]
#hidden is stacked [forward_1, backward_1, forward_2, backward_2, ...]
#outputs are always from the last layer
#hidden [-2, :, : ] is the last of the forwards RNN
#hidden [-1, :, : ] is the last of the backwards RNN
#initial decoder hidden is final hidden state of the forwards and backwards encoder RNNs fed through a linear layer
hidden = torch.tanh(self.fc(torch.cat((hidden[-2,:,:], hidden[-1,:,:]), dim=2)))
#outputs = [sent len, batch size, enc hid dim * 2]
#hidden = [batch size, dec hid dim]
return outputs, hidden
- 在解码器中应用掩码(mask),其他部分保持不变
Attention
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
class Attention(nn.Module):
def __init__(self, enc_hid_dim, dec_hid_dim):
super().__init__()
self.enc_hid_dim = enc_hid_dim
self.dec_hid_dim = dec_hid_dim
self.attn = nn.Linear((enc_hid_dim * 2) + dec_hid_dim, dec_hid_dim)
self.v = nn.Parameter(torch.rand(dec_hid_dim))
def forward(self, hidden, encoder_outputs, mask):
#hidden = [batch size, dec hid dim]
#encoder_outputs = [src sent len, batch size, enc hid dim * 2]
#mask = [batch size, src sent len]
batch_size = encoder_outputs.shape[1]
src_len = encoder_outputs.shape[0]
#repeat encoder hidden state src_len times
hidden = hidden.unsqueeze(1).repeat(1, src_len, 1)
encoder_outputs = encoder_outputs.permute(1, 0, 2)
#hidden = [batch size, src sent len, dec hid dim]
#encoder_outputs = [batch size, src sent len, enc hid dim * 2]
energy = torch.tanh(self.attn(torch.cat((hidden, encoder_outputs), dim=2)))
#energy = [batch size, src sent len, dec hid dim]
energy = energy.permute(0, 2, 1)
#energy = [batch size, dec hid dim, src sent len]
#v = [dec hid dim]
v = self.v.repeat(batch_size, 1).unsqueeze(1)
#v = [batch size, 1, dec hid dim]
attention = torch.bmm(v, energy).squeeze(1)
#attention = [batch size, src sent len]
attention = attention.masked_fill(mask == 0, -1e10)
return F.softmax(attention, dim=1)
- 通过解码器将掩码(mask)应用于注意力的输出
- 重新规范化
注意力向量,使每行总和为1 - 返回注意力
Decoder
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
class Decoder(nn.Module):
def __init__(self, output_dim, emb_dim, enc_hid_dim, dec_hid_dim, dropout, attention):
super().__init__()
self.emb_dim = emb_dim
self.enc_hid_dim = enc_hid_dim
self.dec_hid_dim = dec_hid_dim
self.output_dim = output_dim
self.dropout = dropout
self.attention = attention
self.embedding = nn.Embedding(output_dim, emb_dim)
self.rnn = nn.GRU((enc_hid_dim * 2) + emb_dim, dec_hid_dim)
self.out = nn.Linear((enc_hid_dim * 2) + dec_hid_dim + emb_dim, output_dim)
self.dropout = nn.Dropout(dropout)
def forward(self, input, hidden, encoder_outputs, mask):
#input = [batch size]
#hidden = [batch size, dec hid dim]
#encoder_outputs = [src sent len, batch size, enc hid dim * 2]
#mask = [batch size, src sent len]
input = input.unsqueeze(0)
#input = [1, batch size]
embedded = self.dropout(self.embedding(input))
#embedded = [1, batch size, emb dim]
a = self.attention(hidden, encoder_outputs, mask)
#a = [batch size, src sent len]
a = a.unsqueeze(1)
#a = [batch size, 1, src sent len]
encoder_outputs = encoder_outputs.permute(1, 0, 2)
#encoder_outputs = [batch size, src sent len, enc hid dim * 2]
weighted = torch.bmm(a, encoder_outputs)
#weighted = [batch size, 1, enc hid dim * 2]
weighted = weighted.permute(1, 0, 2)
#weighted = [1, batch size, enc hid dim * 2]
rnn_input = torch.cat((embedded, weighted), dim=2)
#rnn_input = [1, batch size, (enc hid dim * 2) + emb dim]
output, hidden = self.rnn(rnn_input, hidden.unsqueeze(0))
#output = [sent len, batch size, dec hid dim * n directions]
#hidden = [n layers * n directions, batch size, dec hid dim]
#sent len, n layers and n directions will always be 1 in this decoder, therefore:
#output = [1, batch size, dec hid dim]
#hidden = [1, batch size, dec hid dim]
#this also means that output == hidden
assert (output == hidden).all(), print(output.shape, hidden.shape, output[0,0,:25], hidden[0,0,:25])
embedded = embedded.squeeze(0)
output = output.squeeze(0)
weighted = weighted.squeeze(0)
output = self.out(torch.cat((output, weighted, embedded), dim=1))
#output = [bsz, output dim]
return output, hidden.squeeze(0), a.squeeze(1)
- seq2seq需要接受src_len并创建掩码(mask)
- 将掩码传递给解码器以用于
注意力attention的计算 - 从解码器获得
attention并存储在张量中并返回它的值
seq2seq
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
class Seq2Seq(nn.Module):
def __init__(self, encoder, decoder, pad_idx, sos_idx, eos_idx, device):
super().__init__()
self.encoder = encoder
self.decoder = decoder
self.pad_idx = pad_idx
self.sos_idx = sos_idx
self.eos_idx = eos_idx
self.device = device
def create_mask(self, src):
mask = (src != self.pad_idx).permute(1, 0)
return mask
def forward(self, src, src_len, trg, teacher_forcing_ratio=0.5):
#src = [src sent len, batch size]
#src_len = [batch size]
#trg = [trg sent len, batch size]
#teacher_forcing_ratio is probability to use teacher forcing
#e.g. if teacher_forcing_ratio is 0.75 we use teacher forcing 75% of the time
if trg is None:
inference = True
assert teacher_forcing_ratio == 0, "Must be zero during inference"
trg = torch.zeros((100, src.shape[1]),dtype=torch.long).fill_(self.sos_idx).to(self.device)
else:
inference = False
batch_size = src.shape[1]
max_len = trg.shape[0]
trg_vocab_size = self.decoder.output_dim
#tensor to store decoder outputs
outputs = torch.zeros(max_len, batch_size, trg_vocab_size).to(self.device)
#tensor to store attention
attentions = torch.zeros(max_len, batch_size, src.shape[0]).to(self.device)
#encoder_outputs is all hidden states of the input sequence, back and forwards
#hidden is the final forward and backward hidden states, passed through a linear layer
encoder_outputs, hidden = self.encoder(src, src_len)
#first input to the decoder is the <sos> tokens
output = trg[0,:]
mask = self.create_mask(src)
#mask = [batch size, src sent len]
for t in range(1, max_len):
output, hidden, attention = self.decoder(output, hidden, encoder_outputs, mask)
outputs[t] = output
attentions[t] = attention
teacher_force = random.random() < teacher_forcing_ratio
top1 = output.max(1)[1]
output = (trg[t] if teacher_force else top1)
if inference and output.item() == self.eos_idx:
return outputs[:t], attentions[:t]
return outputs, attentions
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
INPUT_DIM = len(SRC.vocab)
OUTPUT_DIM = len(TRG.vocab)
ENC_EMB_DIM = 256
DEC_EMB_DIM = 256
ENC_HID_DIM = 512
DEC_HID_DIM = 512
ENC_DROPOUT = 0.5
DEC_DROPOUT = 0.5
PAD_IDX = SRC.vocab.stoi['<pad>']
SOS_IDX = TRG.vocab.stoi['<sos>']
EOS_IDX = TRG.vocab.stoi['<eos>']
# create model
attn = Attention(ENC_HID_DIM, DEC_HID_DIM)
enc = Encoder(INPUT_DIM, ENC_EMB_DIM, ENC_HID_DIM, DEC_HID_DIM, ENC_DROPOUT)
dec = Decoder(OUTPUT_DIM, DEC_EMB_DIM, ENC_HID_DIM, DEC_HID_DIM, DEC_DROPOUT, attn)
model = Seq2Seq(enc, dec, PAD_IDX, SOS_IDX, EOS_IDX, device).to(device)
optimizer = optim.Adam(model.parameters())
pad_idx = TRG.vocab.stoi['<pad>']
criterion = nn.CrossEntropyLoss(ignore_index=pad_idx)
def train(model, iterator, optimizer, criterion, clip):
model.train()
epoch_loss = 0
for i, batch in enumerate(iterator):
src, src_len = batch.src
trg = batch.trg
optimizer.zero_grad()
output, _ = model(src, src_len, trg)
loss = criterion(output[1:].view(-1, output.shape[2]), trg[1:].view(-1))
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), clip)
optimizer.step()
epoch_loss += loss.item()
return epoch_loss / len(iterator)
def evaluate(model, iterator, criterion):
model.eval()
epoch_loss = 0
with torch.no_grad():
for i, batch in enumerate(iterator):
src, src_len = batch.src
trg = batch.trg
output, _ = model(src, src_len, trg, 0) #turn off teacher forcing
loss = criterion(output[1:].view(-1, output.shape[2]), trg[1:].view(-1))
epoch_loss += loss.item()
return epoch_loss / len(iterator)
N_EPOCHS = 10
CLIP = 10
SAVE_DIR = 'models'
MODEL_SAVE_PATH = os.path.join(SAVE_DIR, 'tut4_model.pt')
best_valid_loss = float('inf')
if not os.path.isdir(f'{SAVE_DIR}'):
os.makedirs(f'{SAVE_DIR}')
for epoch in range(N_EPOCHS):
train_loss = train(model, train_iterator, optimizer, criterion, CLIP)
valid_loss = evaluate(model, valid_iterator, criterion)
if valid_loss < best_valid_loss:
best_valid_loss = valid_loss
torch.save(model.state_dict(), MODEL_SAVE_PATH)
print(f'| Epoch: {epoch+1:03} | Train Loss: {train_loss:.3f} | Train PPL: {math.exp(train_loss):7.3f} | Val. Loss: {valid_loss:.3f} | Val. PPL: {math.exp(valid_loss):7.3f} |')
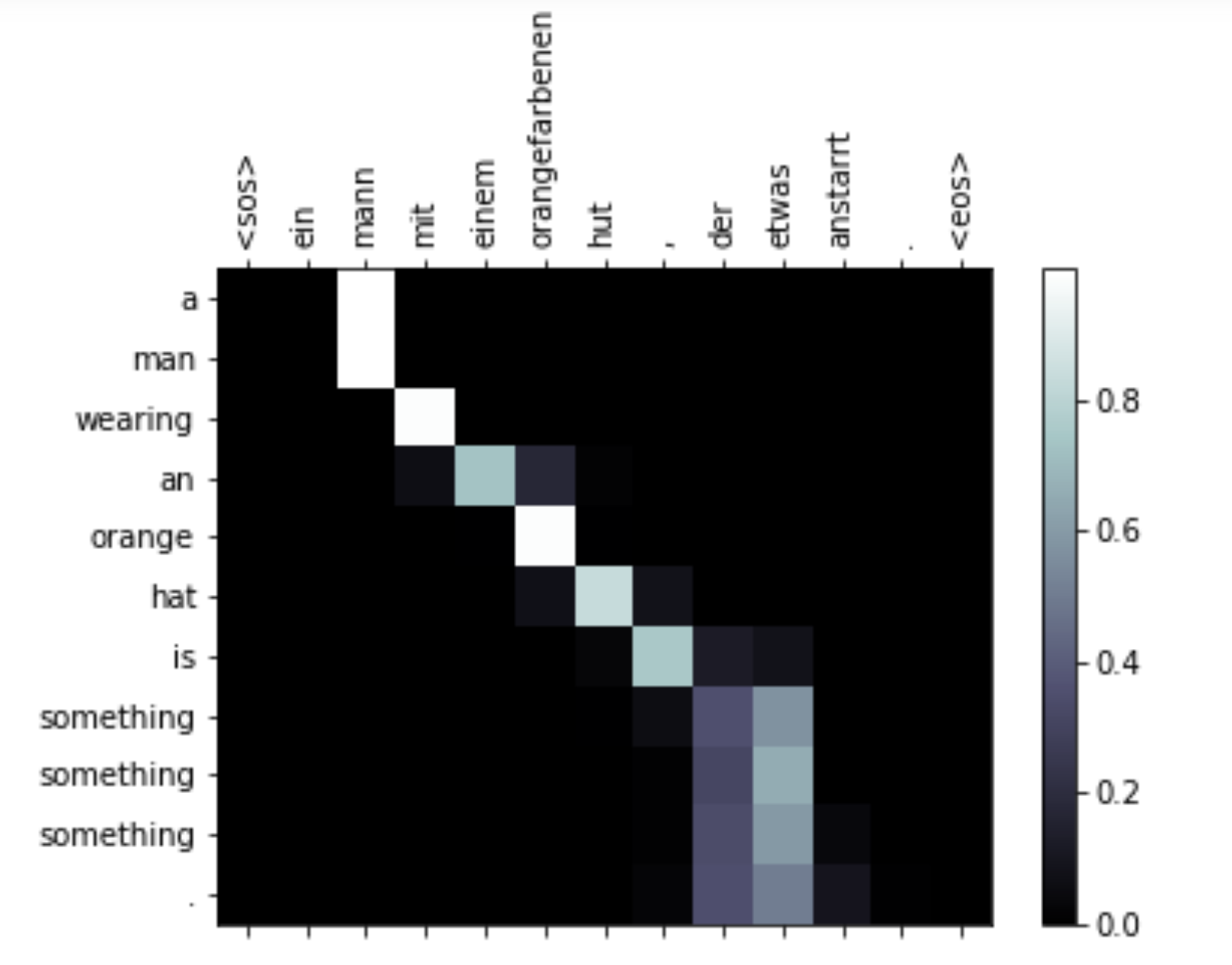
用一个句子来展示mask
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
def translate_sentence(sentence):
tokenized = tokenize_de(sentence) #tokenize sentence
tokenized = ['<sos>'] + [t.lower() for t in tokenized] + ['<eos>'] #add <sos> and <eos> tokens and lowercase
numericalized = [SRC.vocab.stoi[t] for t in tokenized] #convert tokens into indexes
sentence_length = torch.LongTensor([len(numericalized)]).to(device) #need sentence length for masking
tensor = torch.LongTensor(numericalized).unsqueeze(1).to(device) #convert to tensor and add batch dimension
translation_tensor_probs, attention = model(tensor, sentence_length, None, 0) #pass through model to get translation probabilities
translation_tensor = torch.argmax(translation_tensor_probs.squeeze(1), 1) #get translation from highest probabilities
translation = [TRG.vocab.itos[t] for t in translation_tensor][1:] #ignore the first token, just like we do in the training loop
return translation, attention[1:] #ignore first attention array
def display_attention(candidate, translation, attention):
# Set up figure with colorbar
fig = plt.figure()
ax = fig.add_subplot(111)
attention = attention[:len(translation)].squeeze(1).cpu().detach().numpy() #cut attention to same length as translation
cax = ax.matshow(attention, cmap='bone')
fig.colorbar(cax)
# Set up axes
ax.set_xticklabels([''] + ['<sos>'] + [t.lower() for t in tokenize_de(candidate)] + ['<eos>'], rotation=90)
ax.set_yticklabels([''] + translation)
# Show label at every tick
ax.xaxis.set_major_locator(ticker.MultipleLocator(1))
ax.yaxis.set_major_locator(ticker.MultipleLocator(1))
plt.show()
plt.close()
1
2
3
4
5
candidate = ' '.join(vars(train_data.examples[0])['src'])
candidate_translation = ' '.join(vars(train_data.examples[0])['trg'])
print(candidate)
print(candidate_translation)
1
2
ein mann mit einem orangefarbenen hut , der etwas anstarrt .
a man in an orange hat starring at something .
1
2
3
translation, attention = translate_sentence(candidate)
print(translation)
display_attention(candidate, translation, attention)
结果:
1
['a', 'man', 'wearing', 'an', 'orange', 'hat', 'is', 'something', 'something', 'something', '.']